
Scraping By: My YouTube Data Adventure
A while ago, I reached out to Mats, the creator behind the YouTube channel Topfvollgold, offering my help with data scraping. I thought it might be useful for his projects and mentioned that I’d be happy to assist if the need ever arose.
Recently, Mats reached out with an intriguing request: he needed help scraping data directly from YouTube for an interesting video idea. Naturally, I jumped at the opportunity and got straight to work.
This blog documents my journey through the challenges, dead-ends, creative ideas, and eventual success in tackling the task.
Info
The methods and techniques described in this blog article involve scraping data from YouTube, which violates YouTube’s Terms of Service. I do not condone or encourage the use of these methods for any purpose. This article is intended solely for educational purposes to document the technical challenges and solutions involved in data scraping. Readers are advised to respect platform policies and seek lawful and ethical alternatives to achieve their goals.
The YouTube API
My first attempt was to use the official YouTube API. It seemed like the logical starting point for gathering data. As the API is easy to use with various Python packages, I started up a Jupyter notebook and got to work quickly on writing.
from googleapiclient.discovery import build
# Replace with your API key
API_KEY = '[...redacted...]'
# Initialize the YouTube API client
youtube = build('youtube', 'v3', developerKey=API_KEY)
def get_channel_details(channel_id):
# Fetch channel details
request = youtube.channels().list(
part='snippet,contentDetails,statistics',
id=channel_id
)
response = request.execute()
return response
You can iterate over all channels with this function and fetch the channel details. After that, you can get the uploads playlist ID from each channel and pull all video metadata. This works.
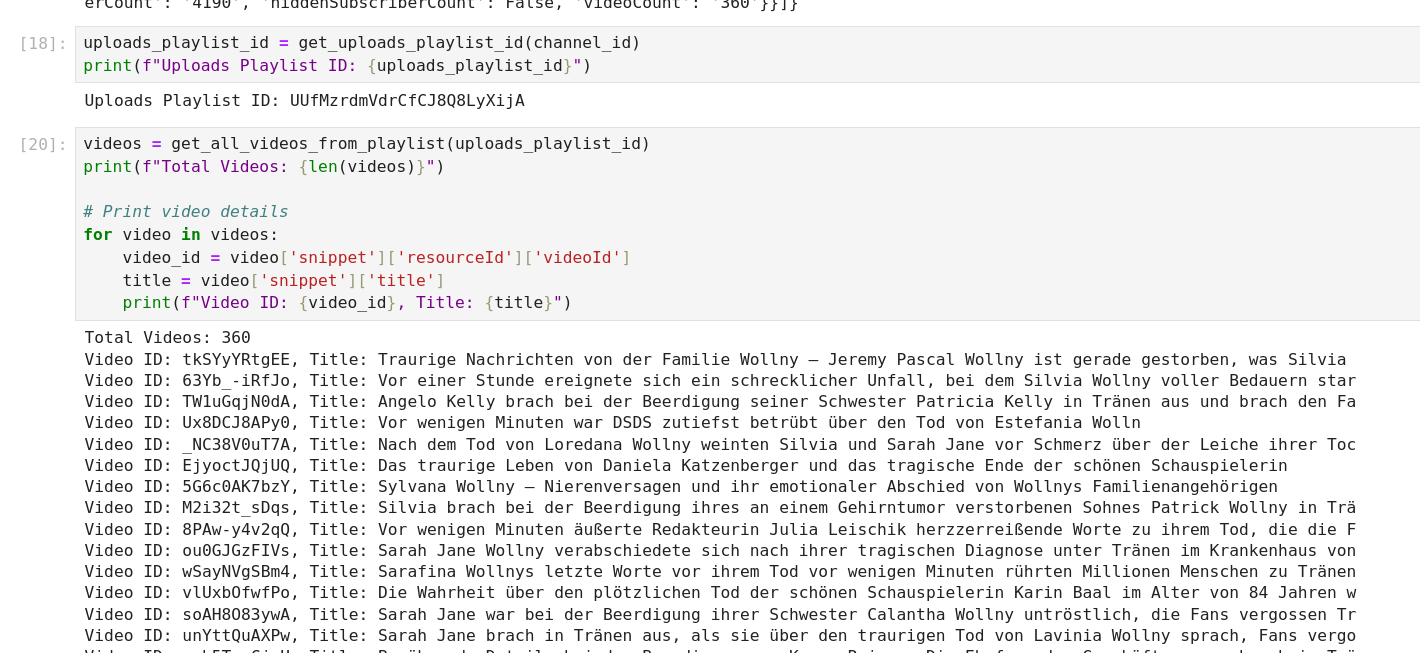
But it will eventually result in a quota boundary hit, as a normal YouTube API Key have a daily quota of 10000 units per day.
Because if we look into the number of video metadata I had to fetch, only from the biggest accounts:
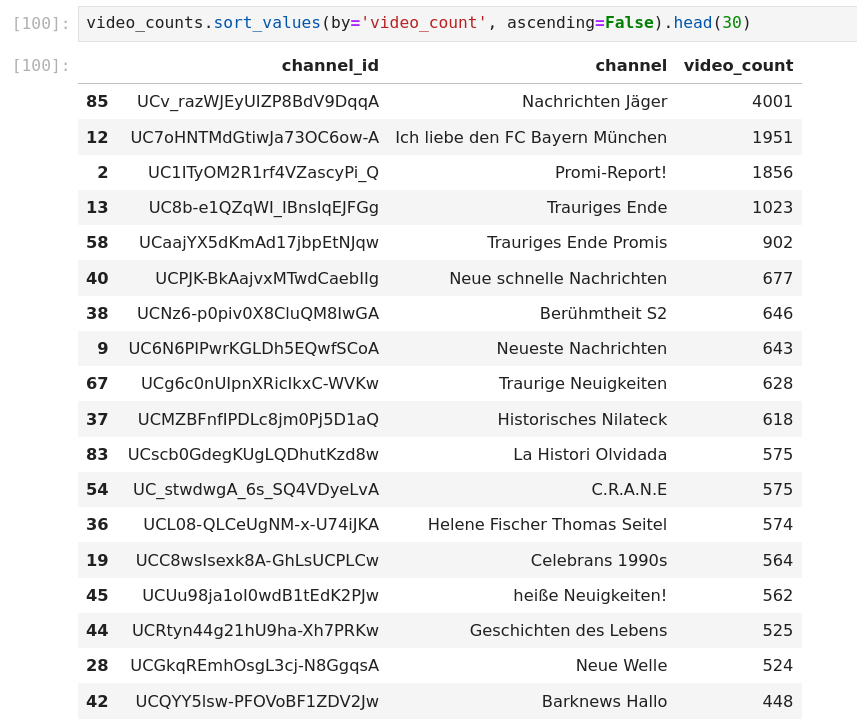
Naturally, I checked what “1 unit” meant. Every action on the YouTube API has a certain quota attached to it. It is not always 1 unit. For example, posting a video will cost you 1600 units, or inserting a channel banner is 50 units. Listing will mostly cost me 1 unit. (Source: https://developers.google.com/youtube/v3/determine_quota_cost?hl=en)
Looking into the number of videos I had to gather, I determined this will never scale. It would be possible to get basic information from this API, but not in a bigger scale. You can request a quota extension for certain projects, but I didn’t have the time for that at this moment and highly doubt I would have gotten a bigger quota extension to fulfill all the needs.
I had to start looking into other options.
Pivoting to yt-dlp
Realizing the limitations of the YouTube API, I decided to switch to a custom scraping solution using yt-dlp. yt-dlp is an actively maintained fork of youtube-dl, which is a command line tool for downloading videos and audio from various platforms like YouTube, Vimeo, and more.
In addition, it is possible to only get the meta-information of a video, which seemed like a good fit for me. Early results were promising, and I felt optimistic.
The first implementation was really naive one, which fetches a list of all videos from the YouTube channels and takes a simple yt-dlp-command to get all metadata from those videos.
def fetch_video_metadata(video_id):
"""Fetch metadata for a YouTube video using yt-dlp."""
try:
ydl_opts = {'quiet': True, 'no_warnings': True, 'format': 'best', 'dump_single_json': True}
with YoutubeDL(ydl_opts) as ydl:
url = f'https://www.youtube.com/watch?v={video_id}'
info = ydl.extract_info(url, download=False)
return info
except Exception as e:
logger.error(f"Error fetching metadata for {video_id}: {e}")
return None
It seemed to work until a got yt-dlp error’ing out and calling me bot. I was suddenly asked to sign in. Fortunately, yt-dlp as a feature to use a YouTube Account to get all the information.
I got a few requests further, until my account was blocked, and I was back to square one.
The Bot Detection Wall
Determined to find a solution, I pivoted again—this time back to anonymous scraping. I discovered, that not the whole IP Address was flagged as bot, you were only rate limited to a couple of minutes. In addition, to avoid detection, I distributed the workload across multiple clients, reducing the risk of any single client being flagged. Even if a client was getting flagged, the idea was to stop the process of this client for a couple of minutes and try again. If it is still flagged, up the wait time for the next retry.
That should be an effective wait to counter the bot detection wall.
Redis Environment for Coordinated Clients
To manage the distributed setup, I set up a Redis Server which was openly accessible from various IP Addresses. This allowed me to coordinate multiple clients effectively.
I pushed all Videos IDs into a Redis List and Pop’ed them from this list with each client to get the meta information. Afterward, I pushed the gained metadata back into Redis. Therefore, this Redis Server was my single source of truth.
It tracked what was already fetched, what was still to be fetched and all the information gained from a video with yt-dlp. (Source: https://github.com/nv1t/youtube-fetch/blob/main/redis_fetch_meta.py)
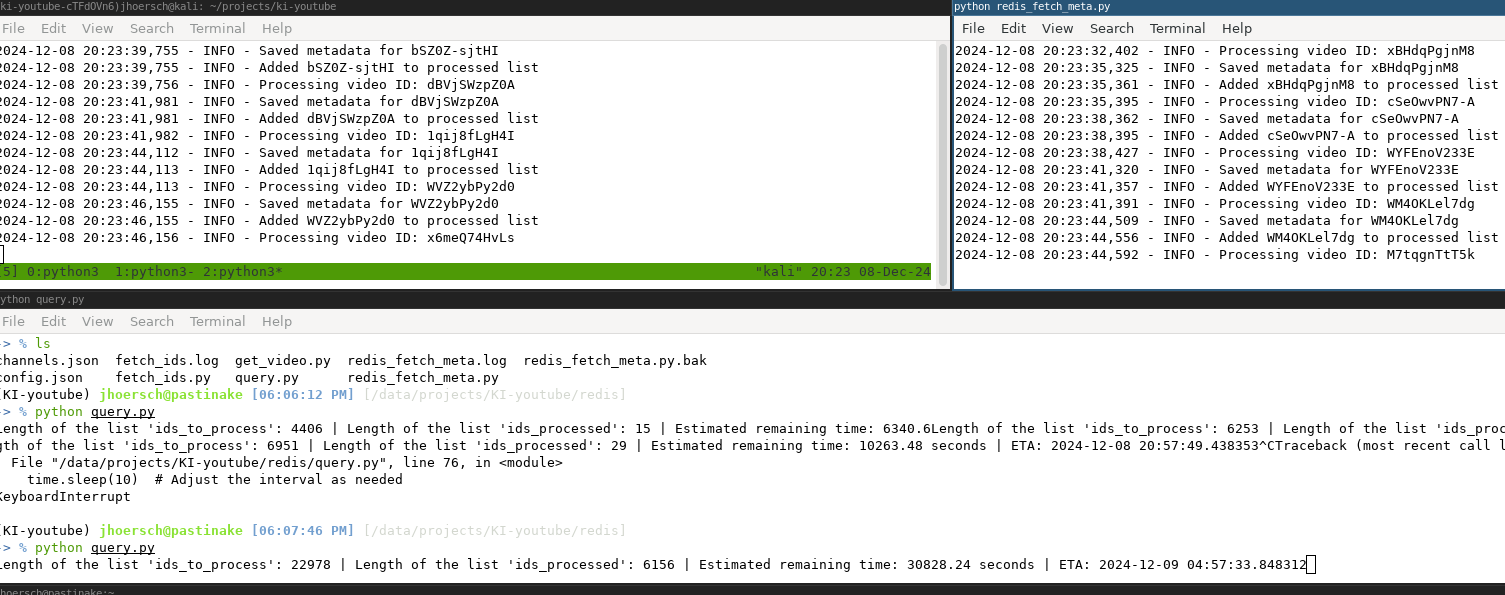 I got a pretty efficient way of distributing all those requests.
I got a pretty efficient way of distributing all those requests.
This worked flawlessly, until it didn’t…
The Redis Crash: A Costly Mistake
I let this run overnight because I didn’t want to spin up multiple agents and was fine with 7–8 hours of waiting. The next morning: Redis died. Because I only set up a Redis instance in a docker container with no persistence storage, the data was gone with the Redis and everything lost.
Something went wrong, but I didn’t have any clue. So I restarted the processes and watched it like a hawk, until I did see the Ram usage climbing in the Redis process.
It struck me: I pushed all information received from yt-dlp into a key <youtubeid>:metainformation in Redis. I never pull or delete this data. There is the possibility to filter this data, but I am more the “get me everything and let me filter it later”-kind of guy.
So I had to have a process which takes all the meta information, pulls them from Redis and save them into onto disk into some kind of Database.
The Resilient Solution: TinyDB and Disk Storage
Therefore, I added a small script which pops a YouTube ID from the Redis List, pulls the meta information from Redis, parses them and saves the original information to a file (for later filtering), and filters relevant information. All of this is saved into a TinyDB.
while True:
video_id = redis_client.rpop(IDS_PROCESSED) # Pop the last ID from the list
if not video_id:
logging.info("No more video IDs left to process.")
break
metadata_key = f"{video_id}:metainformation"
metadata_json = redis_client.get(metadata_key)
if metadata_json:
try:
metadata = json.loads(metadata_json)
metadata_video = {
'id': video_id,
'title': metadata.get('title'),
'description': metadata.get('description'),
'duration': metadata.get('duration'),
'like_count': metadata.get('like_count'),
'view_count': metadata.get('view_count'),
'channel': metadata.get('channel'),
'channel_id': metadata.get('channel_id'),
'timestamp': metadata.get('timestamp'),
}
# Hash video_id for the file name
hashed_video_id = encode_video_id_hash(video_id)
# Write raw metadata to a file
output_file = os.path.join(OUTPUT_DIR, f"{hashed_video_id}.json")
with open(output_file, 'w') as f:
f.write(metadata_json)
logging.info(f"Raw metadata for video ID {video_id} written to {output_file}.")
# Insert metadata into TinyDB
video_table.upsert(metadata_video, where('id') == video_id)
logging.info(f"Processed and stored metadata for video ID {video_id}.")
redis_client.delete(metadata_key)
except json.JSONDecodeError as e:
logging.warning("Failed to decode metadata for video ID %s: %s", video_id, e)
else:
logging.warning("No metadata found for video ID %s", video_id)
This results in really nice and sorted data.

Now I was able to let it rip, and so I did:

What to do now?
Mat has already begun talking about this data in his recent video “So krass werden wir (jetzt schon) mit KI belogen” (https://www.youtube.com/watch?v=rRT5PfxbVC8).
But this is only the beginning. I tried experimenting with sentiment analysis and AI prompting to get further information from this metadata: classifying people mentioned in the titles, how often they died or got pregnant. (See References for this)
Pushing this data into a pandas dataframe is my last action for this post
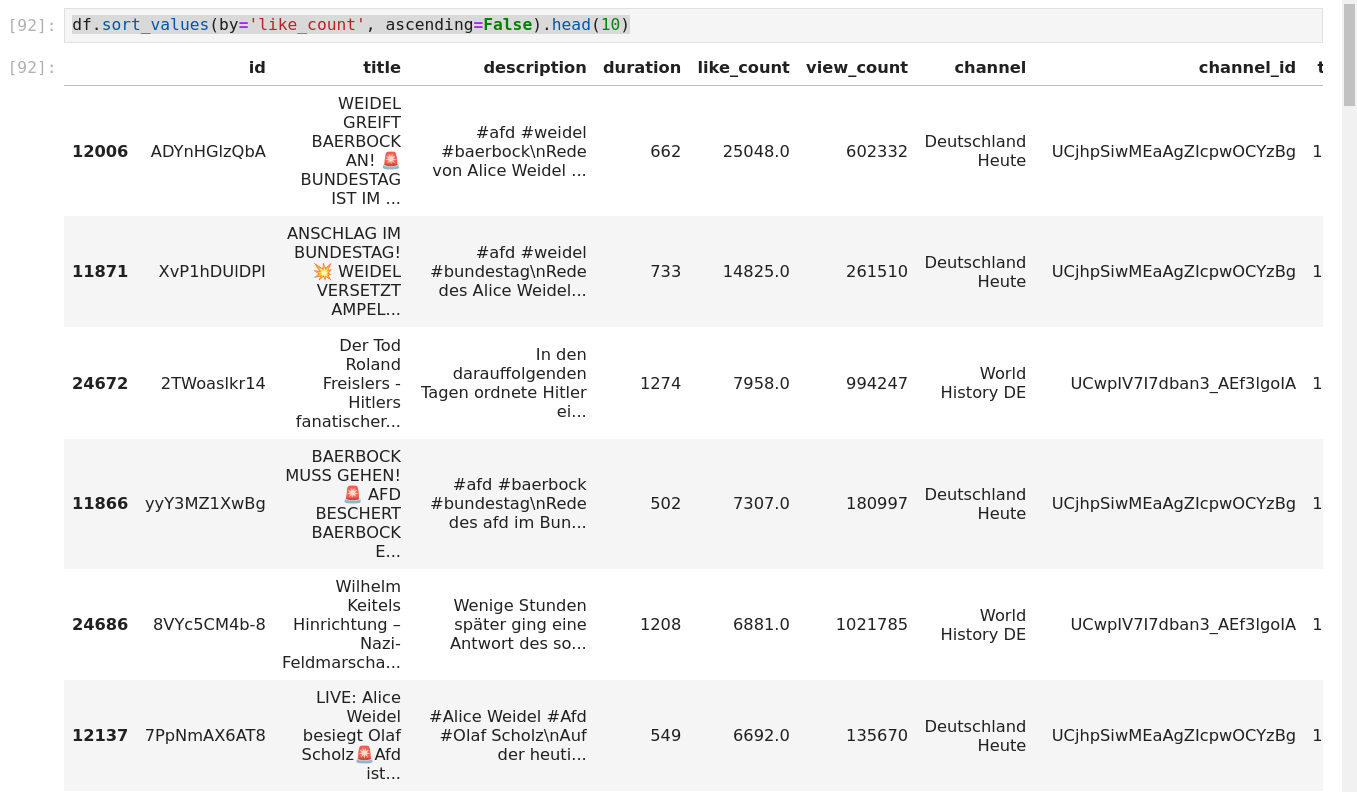
As this would be a whole new video, blog post, or both.
This journey was already a rollercoaster of challenges and learning opportunities. From encountering rate limits to bot detection, and from losing data to building a kind of resilient system, every step reminded me of something valuable.
Reflections and Revelation
- It should be possible to spin up ec2 instances to make this even bigger and faster.
- BUT: Always respect platform policies and consider ethical alternatives!
- Running Redis in docker without data persistence is fine for cache and short storage, but not for long
- AI YouTube Videos are currently popping up like crazy and a lot of stuff in the style of the rainbow press.
- Embrace failure as part of the learning process.
- Embrace ditching ideas for a fresh start or another saying: “Choose a path that still has potential for growth.”
I’m grateful for the opportunity to assist Mats and look forward to analyzing this data.
References
- https://developers.google.com/youtube/v3/determine_quota_cost?hl=en - YouTube Quota
- https://github.com/msiemens/tinydb - TinyDB
- https://github.com/oliverguhr/german-sentiment - Broad-Coverage German Sentiment Classification Model for Dialog Systems
- using https://github.com/oliverguhr/german-sentiment-lib for sentiment analysis
- https://medium.com/@tsvetelina1/sentiment-analysis-dashbaord-on-german-media-2022-2023-e6316f900e47 uses this library.
- https://www.youtube.com/watch?v=rRT5PfxbVC8 - So krass werden wir (jetzt schon) mit KI belogen
- https://github.com/nv1t/youtube-fetch Source Code of this Project
so long