
Get me all the maps
Storyline
It all started with a simple question from my beloved girlfriend: “Is it possible to download the entire map from this page?”. Okok…we have to look back a little bit. She was asked by a friend of ours to scan an old map of an area in the local university library.
But: Scanning such a massive picture would cost ~40 Euro and nobody was willing to pay that. I can understand that nearly every scan could damage the map, so, wouldn’t it be a better option to use an already scanned one?
The search began and it was successful. A Czech website old maps had this map in it’s entirety on their page.
The only crux: It was in tiles and viewable like google maps. No complete picture in high resolution was anywhere to be found.
The search for all the pictures
If you look into the loading of the pictures though, you clearly can see the naming convention.
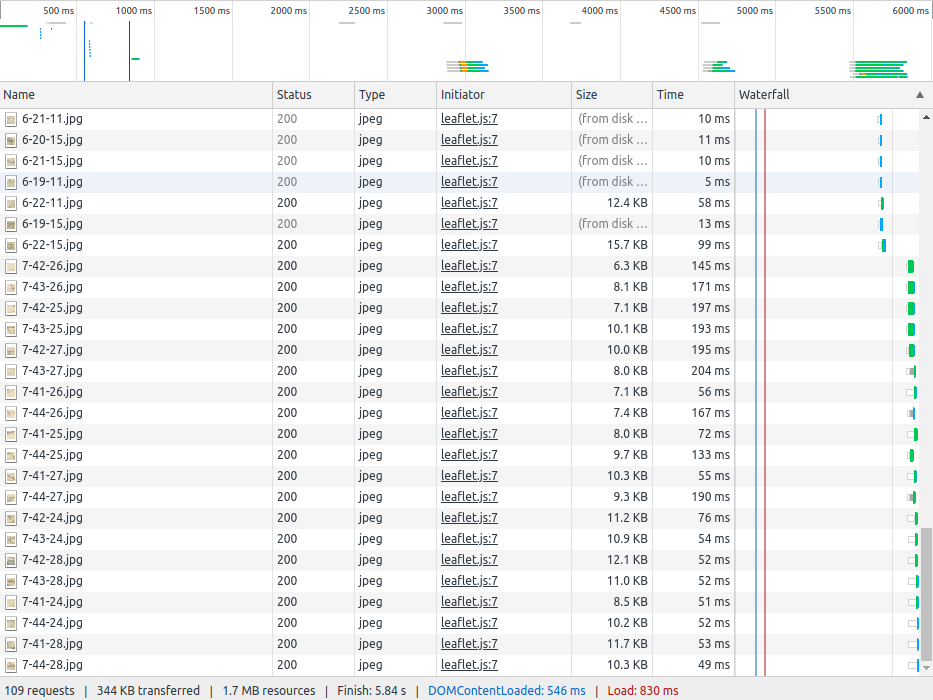
It is a pretty easy one as well, $zoomlevel-$x-$y.jpg. puh, we are in luck.
Now we have 86 rows and 71 columns to deal with, resulting in ~6300 pictures. That makes a hell lot of pictures and a lot of requests to this server.
Downloading individual pictures
Let’s just plug that into a double for-loop and download it. Easy enough.
Side-note: They are even nice enough to open this up through an Access-control-allow-origin wildcard.
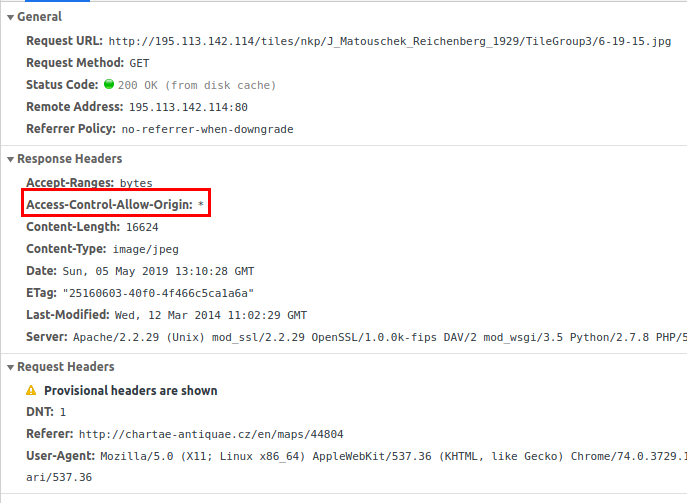
It’s never that easy…NEVER!
Subdirectories
If you look closer at all the pictures, the URL isn’t as clear as i made it out to be. In fact it looks like: http://$server/TileGroup0/7-1-0.jpg. There are subdirectories named TileGroups: /TileGroup%d/7-%d-%d.jpg. TileGroups are predictable, but i am to lazy to reverse that. Therefore, i remember the last TileGroup, i am in and increment that, if i can’t find the relevant file in this TileGroup.
It is a nicer brute force at this point.
import requests
import time
import os
import sys
NAME = ""
URL = "http://$server/"
MAX_TITLE_GROUPS = 32
MAX_X = 86
MAX_Y = 71
first_find = 0 # Last TileGroup
fileLoaded = False
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',
'Referer': 'http://chartae-antiquae.cz/' # This is another valid field
}
with open("%s.log" % (NAME),'rb') as fh:
first_find = int(fh.read())
fileLoaded = True
os.remove("%s.log" % (NAME))
for x in range(MAX_X+1):
if not fileLoaded:
first_find = 0
for y in range(MAX_Y+1):
for i in range(first_find,MAX_TITLE_GROUPS+1):
if os.path.isfile("%s/7-%d-%d.jpg" % (NAME,x,y)):
print("7-%d-%d.jpg already downloaded" % (x,y))
break
url = URL+"/TileGroup%d/7-%d-%d.jpg" % (i,x,y)
try:
r = requests.get(url, headers=headers, timeout=2)
print("[%d] %s" % (r.status_code, url))
if r.status_code == 200:
first_find = i
fileLoaded = False
open("%s/7-%d-%d.jpg" % (NAME,x,y), 'wb').write(r.content)
time.sleep(1.5)
break
else:
time.sleep(1)
except:
print("WTF WENT WRONG")
open("%s.log" % (NAME),'wb').write(str(first_find))
sys.exit(1)
But wait. There is more.
Rate Limiting
You could have guessed it: they have rate limiting against scum like me. It is an annoyance and i didn’t find any good way around it. I tried random sleeps, waiting long enough, referrer, user-agents, etc. But the script failed now and then. Nothing worked. Therefore it keeps a log and checks all the already downloaded files.
The easiest option was to check the exit code of the python script and retry after 10sec. Easy and Dirty.
#!/bin/bash
until python get.py; do
echo "Retry in 10sec"
sleep 10
done;
What about ~6k 25x25px pictures
I downloaded about ~6300 pictures which are already in a perfect shape. I have the position in the grid and just have to assemble them.convert to the rescue! I could have used PIL or similar python libraries, but c’mon…why not just use a simple bash script to assemble.
It assembles individual columns and assembles all columns into one big picture.
#!/bin/bash
if [ -z "${1}" ]; then
echo "Usage: ${0} <directory>"
exit 1;
fi;
mkdir -p "${1}/merged.layer.1/"
rm "${1}/merged.layer.1/*.jpg"
if [ -f "${1}.jpg" ]; then
rm "${1}.jpg"
fi;
highest=$(ls ${1}/*.jpg | sort -V | tail -n 1 | awk -F- '{print $2}')
for i in `seq 0 $highest`; do
convert -append $(ls -1 "${1}/7-$i-*.jpg" | sort -V) "${1}/merged.layer.1/7-${i}.jpg";
done;
convert +append $(ls -1 "${1}/merged.layer.1/*.jpg" | sort -V) ${1}.jpg
Final thoughts
Yes, you can send them an email to ask nicely for this picture. At this point i don’t have any idea if they charge something for that. I heard rumours you get them without any costs, if you don’t want to use them in a commercial manner. They really ask rigorous questions about the usage part. And you have to sign a form for that.
If you want to look at the map, i would highly suggest using the online viewer provided: http://chartae-antiquae.cz/
We wanted to print and this was not possible without downloading unfortunately. Waiting wasn’t an option either. Tight timeline for a present and a final DinA0 print.
so long